ACGD: Visual Multitask Policy Learning with Asymmetric Critic Guided Distillation
Krishnan Srinivasan* Jie Xu Henry Ang Eric Heiden Dieter Fox Jeannette Bohg Animesh Garg
Stanford University NVIDIA Georgia Tech
Abstract
ACGD introduces a novel approach to visual multitask policy learning by leveraging asymmetric critics to guide the distillation process. Our method trains single-task expert policies and their corresponding critics using privileged state information. These experts are then used to distill a unified multi-task student policy that can generalize across diverse tasks. The student policy employs a VQ-VAE architecture with a transformer-based encoder and decoder, enabling it to predict discrete action tokens from image observations and robot states. We evaluate ACGD on three challenging multi-task domains—MyoDex, BiDex, and OpDex—and demonstrate significant improvements over baseline methods such as BC-RNN+DAgger, ACT, and MT-PPO. ACGD achieves a 10-15% performance boost across various dexterous manipulation benchmarks, showcasing its effectiveness in scaling to high degrees of freedom and complex visuomotor tasks.
Video
Motivation
Multitask policy learning in robotics aims to create versatile agents capable of performing a variety of tasks using shared representations. However, existing approaches often struggle with scalability, generalization, and efficient training. ACGD addresses these challenges by introducing asymmetric critics that provide task-specific guidance during the distillation process, enabling the student policy to learn effectively from diverse expert behaviors without requiring extensive environment interactions.
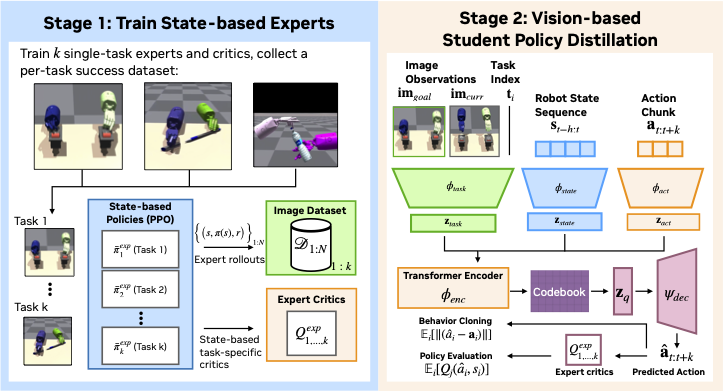
Method Overview
ACGD consists of two main stages:
- Train single-task expert policies and critics using privileged state information.
- Distill a multi-task student policy using expert rollouts and critics.
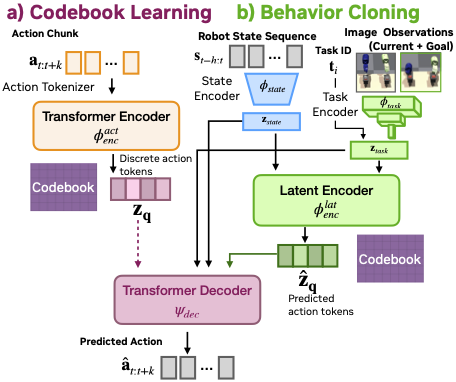
The student policy utilizes a VQ-VAE architecture with a transformer encoder and decoder to predict discrete action tokens from image observations and robot states. This architecture facilitates effective generalization across multiple tasks by learning a shared representation space.
Experimental Results
ACGD was evaluated on three multi-task domains:
- MyoDex: 10 tasks using a single hand with 39 DoF muscle tendons.
- BiDex: 3 tasks using two Shadow hands with 52 DoF total.
- OpDex: 2 tasks using an AllegroHand with 22 DoF and operable articulated objects.
ACGD outperforms baseline methods like BC-RNN+DAgger, ACT, and MT-PPO on various dexterous manipulation benchmarks, achieving a 10-15% improvement over these algorithms. The results highlight ACGD's ability to scale effectively with the number of tasks and demonstrations, as well as its proficiency in handling high-DoF multi-task visuomotor skills.

Videos
BibTeX
@misc{
srinivasan2024acgd,
title={ACGD: Visual Multitask Policy Learning with Asymmetric Critic Guided Distillation},
author={Krishnan Srinivasan and Jie Xu and Eric Heiden and Henry Ang and Dieter Fox and Jeannette Bohg and Animesh Garg},
year={2024},
howpublished={\url{https://your-paper-link.com}}
}